-
Python 教程
- Python 主页
- Python 简介
- Python 入门
- Python 语法
- Python 注释
- Python 变量
- Python 数据类型
- Python 数字
- Python 类型转换
- Python 字符串
- Python 布尔值
- Python 运算符
- Python 列表
- Python 元组
- Python 集合
- Python 字典
- Python If...Else
- Python While 循环
- Python For 循环
- Python 函数
- Python Lambda
- Python 数组
- Python 类/对象
- Python 继承
- Python 迭代器
- Python 多态
- Python 作用域
- Python 模块
- Python 日期
- Python 数学
- Python JSON
- Python 正则表达式
- Python PIP
- Python Try...Except
- Python 用户输入
- Python 字符串格式化
- 文件处理
- Python 模块
- Python Matplotlib
- 机器学习
- Python MySQL
- Python MongoDB
- Python 参考
- 模块参考
- Python 如何使用
- Python 示例
机器学习 - K 最近邻 (KNN)
在此页面上,W3schools.com 与纽约数据科学院,为我们的学生提供数字培训内容。
克尼恩
KNN 是一种简单的监督机器学习 (ML) 算法,可用于分类或回归任务 - 并且也经常用于缺失值插补。它基于这样的想法:最接近给定数据点的观测值是数据集中最多 "similar" 的观测值,因此我们可以根据最接近的现有点的值对不可预见的点进行分类。通过选择K,用户可以选择算法中使用的附近观测值的数量。
在这里,我们将向您展示如何实现 KNN 算法进行分类,并展示不同的值如何K影响结果。
它是如何工作的?
K是要使用的最近邻居的数量。对于分类,使用多数投票来确定新观察结果应属于哪一类。较大的值K通常比非常小的值对异常值更稳健,并且产生更稳定的决策边界(K=3会比K=1,这可能会产生不良结果。
示例
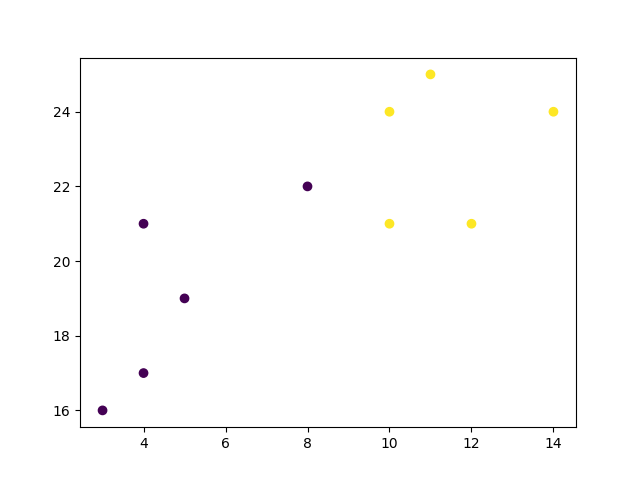
首先可视化一些数据点:
import matplotlib.pyplot as plt
x = [4, 5, 10, 4, 3, 11, 14 , 8, 10, 12]
y = [21, 19, 24, 17, 16, 25, 24, 22, 21, 21]
classes = [0, 0, 1, 0, 0, 1, 1, 0, 1, 1]
plt.scatter(x, y, c=classes)
plt.show()
结果
广告
现在我们拟合 KNN 算法,K=1:
from sklearn.neighbors import KNeighborsClassifier
data = list(zip(x, y))
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(data, classes)
并用它来对新数据点进行分类:
示例
new_x = 8
new_y = 21
new_point = [(new_x, new_y)]
prediction = knn.predict(new_point)
plt.scatter(x + [new_x], y + [new_y], c=classes + [prediction[0]])
plt.text(x=new_x-1.7, y=new_y-0.7, s=f"new point, class: {prediction[0]}")
plt.show()
结果

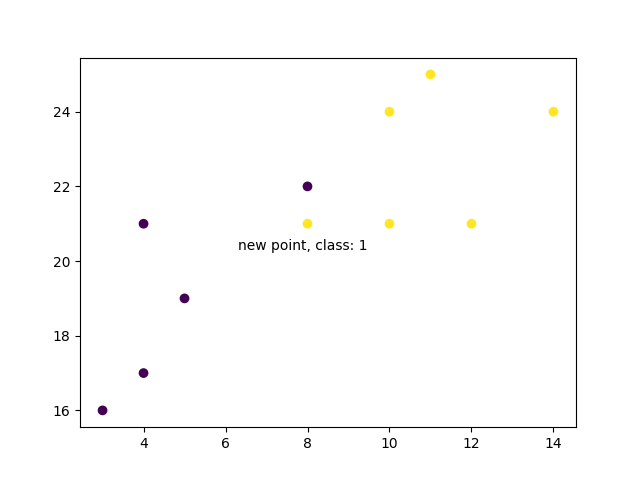
现在我们做同样的事情,但使用更高的 K 值来改变预测:
示例
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(data, classes)
prediction = knn.predict(new_point)
plt.scatter(x + [new_x], y + [new_y], c=classes + [prediction[0]])
plt.text(x=new_x-1.7, y=new_y-0.7, s=f"new point, class: {prediction[0]}")
plt.show()
结果
示例解释
导入您需要的模块。
您可以在我们的中了解 Matplotlib 模块《Matplotlib 教程。
scikit-learn 是一个流行的 Python 机器学习库。
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
创建类似于数据集中变量的数组。我们有两个输入特征(x和y)然后是目标类(class)。预先标记为目标类别的输入特征将用于预测新数据的类别。请注意,虽然我们在这里仅使用两个输入特征,但此方法将适用于任意数量的变量:
x = [4, 5, 10, 4, 3, 11, 14 , 8, 10, 12]
y = [21, 19, 24, 17, 16, 25, 24, 22, 21, 21]
classes = [0, 0, 1, 0, 0, 1, 1, 0, 1, 1]
将输入特征转化为一组点:
data = list(zip(x, y))
print(data)
结果:
[(4, 21), (5, 19), (10, 24), (4, 17), (3, 16), (11, 25), (14, 24), (8, 22), (10, 21), (12, 21)]
使用输入特征和目标类,我们使用 1 个最近邻在模型上拟合 KNN 模型:
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(data, classes)
然后,我们可以使用相同的 KNN 对象来预测新的、不可预见的数据点的类别。首先我们创建新的 x 和 y 特征,然后调用knn.predict()在新数据点上获得 0 或 1 类:
new_x = 8
new_y = 21
new_point = [(new_x, new_y)]
prediction = knn.predict(new_point)
print(prediction)
结果:
[0]
当我们绘制所有数据以及新点和类别时,我们可以看到它被标记为蓝色,并带有1类。文字注释只是为了突出显示新点的位置:
plt.scatter(x + [new_x], y + [new_y], c=classes + [prediction[0]])
plt.text(x=new_x-1.7, y=new_y-0.7, s=f"new point, class: {prediction[0]}")
plt.show()
结果:
然而,当我们将邻居数量更改为 5 时,用于对新点进行分类的点数会发生变化。因此,新点的分类也是如此:
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(data, classes)
prediction = knn.predict(new_point)
print(prediction)
结果:
[1]
当我们将新点的类别与旧点一起绘制时,我们注意到颜色已根据关联的类别标签发生变化:
plt.scatter(x + [new_x], y + [new_y], c=classes + [prediction[0]])
plt.text(x=new_x-1.7, y=new_y-0.7, s=f"new point, class: {prediction[0]}")
plt.show()
结果:
截取页面反馈部分,让我们更快修复内容!也可以直接跳过填写反馈内容!