数据科学 - 线性回归案例
案例:使用 Duration + Average_Pulse 来预测 Calorie_Burnage
创建一个以 Average_Pulse 和 Duration 作为解释变量的线性回归表:
示例
import pandas as pd
import statsmodels.formula.api as smf
full_health_data = pd.read_csv("data.csv", header=0, sep=",")
model = smf.ols('Calorie_Burnage ~ Average_Pulse + Duration', data = full_health_data)
results = model.fit()
print(results.summary())
亲自试一试 »
示例解释:
- 将库 statsmodels.formula.api 导入为 smf。 Statsmodels 是 Python 中的一个统计库。
- 使用 full_health_data 集。
- 使用 smf.ols() 创建基于普通最小二乘法的模型。请注意,解释变量必须先写在括号中。使用 full_health_data 数据集。
- 通过调用.fit(),您可以获得变量结果。这包含了有关回归模型的大量信息。
- 调用summary()来获取包含线性回归结果的表。
输出:
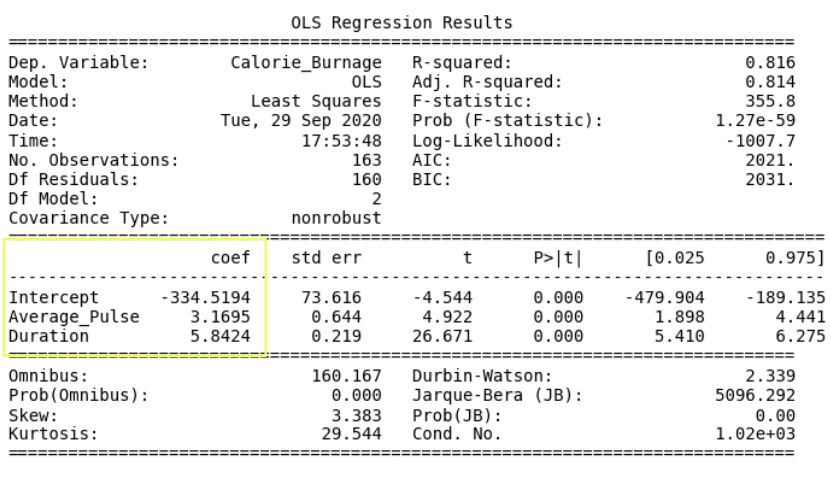
线性回归函数可以在数学上重写为:
Calorie_Burnage = Average_Pulse * 3.1695 + Duration * 5.8424 - 334.5194
四舍五入到小数点后两位:
Calorie_Burnage = Average_Pulse * 3.17 + Duration * 5.84 - 334.52
在 Python 中定义线性回归函数
在 Python 中定义线性回归函数来执行预测。
如果满足以下条件,什么是 Calorie_Burnage:
- 平均脉搏是 110,训练时间是 60 分钟?
- 平均脉搏是 140,训练时间是 45 分钟?
- 平均脉搏是 175,训练时间是 20 分钟?
示例
def Predict_Calorie_Burnage(Average_Pulse, Duration):
return(3.1695*Average_Pulse + 5.8434 * Duration - 334.5194)
print(Predict_Calorie_Burnage(110,60))
print(Predict_Calorie_Burnage(140,45))
print(Predict_Calorie_Burnage(175,20))
亲自试一试 »
答案:
- 平均脉搏为 110,训练持续时间为 60 分钟 = 365 卡路里
- 平均脉搏为 140,训练持续时间为 45 分钟 = 372 卡路里
- 平均脉搏为 175,训练持续时间为 20 分钟 = 337 卡路里
访问系数
看一下系数:
- 如果 Average_Pulse 增加 1,则 Calorie_Burnage 会增加 3.17。
- 如果持续时间增加 1,卡路里消耗量会增加 5.84。
访问 P 值
查看每个系数的 P 值。
- Average_Pulse、持续时间和截距的 P 值为 0.00。
- 所有变量的 P 值均具有统计显着性,因为它小于 0.05。
所以这里我们可以得出结论,Average_Pulse和Duration与Calorie_Burnage有关系。
调整后的 R 平方
如果我们有多个解释变量,R 平方就会出现问题。
如果我们添加更多变量,R 平方几乎总是会增加,并且永远不会减少。
这是因为我们在线性回归函数周围添加了更多数据点。
如果我们添加不影响 Calorie_Burnage 的随机变量,我们就有可能错误地得出线性回归函数非常合适的结论。调整后的 R 平方针对此问题进行了调整。
因此,如果我们有多个解释变量,最好查看调整后的 R 平方值。
调整后的 R 平方为 0.814。
R-Squared 的值始终在 0 到 1(0% 到 100%)之间。
- 高 R 平方值意味着许多数据点接近线性回归函数线。
- R 平方值较低意味着线性回归函数线不能很好地拟合数据。
结论:模型与数据点拟合得很好!
恭喜!您现在已经完成了数据科学库的最后一个模块。
截取页面反馈部分,让我们更快修复内容!也可以直接跳过填写反馈内容!